用Python做机试题的一些基础知识
输入输出部分
import sys
# 定行输入
for i in range(n):
line = sys.stdin.readline().strip() # 每次仅读取一行,别忘strip去除最后回车
# 不定行输入
for line in sys.stdin: #会一直读到输入结束,别忘strip去除最后回车
str_in = line.strip()
# input输入
for i in range(n):
str_item = input().strip() # input()读取到空格和回车都认为是分隔符,别忘strip去除最后回车数据处理部分
# 移除字符串头尾指定的字符或字符序列(默认为空格或换行符),返回生成的新字符串
str1 = str_in.strip()
# 去除首尾字符串01
str2 = str_in.strip("01");
# 通过指定分隔符对字符串进行切片,返回分割后的字符串列表
str_list = str_in.split(" ")
# 使用map对列表进行处理,会根据提供的函数对指定序列做映射,在Python3中返回迭代器,故需要再转换成列表
int_list1 = list(map(int,str_list))
# 也可以使用lambda表达式来进行更复杂的操作,例如转换为整数后再平方
int_list2 = list(map(lambda x:int(x)**2, str_list))
# 进制转换:其他进制字符串转十进制
int1 = int('0xA',16) # 10
int2 = int('1001',2) # 9
int3 = int('17',8) # 15
# 进制转换:十进制转其他进制字符串
str_hex = hex(15) # 0xf
str_bin = bin(2) # 0b10
str_oct = oct(7) # 0o7
#对数
import math
math.log(2.7) #底数默认e
# ASCII码与字符相互转换: ord()获取ASCII码,chr()转字符
print("a的ASCII码为", ord('a'))
print("101对应的字符为", chr(101))
# 浮点数转整型
# int 向0取整
int(-0.5) # 0
int(-0.9) # 0
int(0.5) # 0
int(0.9) # 0
# round 四舍六入,五向偶取整
round(0.5) # 0
round(0.6) # 1
round(1.5) # 2
round(-2.5) # -2
round(-1.4) # -1
round(-1.6) # -2
import math
# math.floor 向下取整(向数轴负方向)(与整除符号//一样)
math.floor(0.9) # 0
math.floor(-0.9) # -1
# math.ceil 向上取整(向数轴正方向)
math.ceil(0.3) # 1
math.ceil(0.5) # 1
math.ceil(-0.5) # 0
math.ceil(-0.9) # 0
# 输入时转换示例1:将字符串“1 2 3 4”转换为整型列表
for line in sys.stdin:
a = list(map(int,line.strip().split(" "))) # [1, 2, 3, 4]
# 输入时转换示例2:将字符串“1 2 3 4”内的数字平方后,转换为十六进制,得到列表
for line in sys.stdin:
a = list(map(lambda x:hex(int(x)**2),line.strip().split(" ")))
#['0x1', '0x4', '0x9', '0x10']
排序
#Python3中list.sort()和sorted()中的cmp参数已经被移除,此处即为Python3
#list.sort()没有返回值,自身排序
list_in.sort(key=None, reverse=False)
#sorted()返回一个新的,参数接受任何可迭代对象
sorted_list = sorted(list_in, key=None, reverse=False)
#按key排序使用例子:
list1.sort(key=lambda x:x[1])
list1_sorted = sorted(list1, key=lambda x:x[1])容器相关
#列表
a = [123,"abc"] #可以有不同类型的元素
dp = [[0 for i in range(3)] for j in range(3)] #创建二维列表[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
list.append(x) #把一个元素添加到列表的结尾
list.index(x) #返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。
list.count(x) #返回 x 在列表中出现的次数。
list.sort() #对列表中的元素进行排序。
list.reverse() #倒排列表中的元素。
list.pop() #返回最后一个元素。元素随即从列表中被移除。可以和append配合完成栈功能
list.remove(x) #用于移除列表中某个值的第一个匹配项。x是值,不是索引。
list.insert(index, obj) # 将对象插入列表指定位置,index = 0就是插入在最前面
for i, v in enumerate(['tic', 'tac', 'toe']): #按索引遍历列表
print(i, v)
#集合
#创建
set1 = {1, 2, 3, 4}# 直接使用大括号创建集合
set2 = set([4, 5, 6, 7]) # 使用 set() 函数从列表创建集合,即从列表转换为集合
set3 = set() #注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
#添加元素
set1.add(5)
#移除元素,如果元素不存在会发生错误
s.remove(x)
#移除元素,不存在不会报错
s.discard(x)
#set遍历可使用简单的for in
for i in s:
print i
#字典
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
for k, v in knights.items(): #使用dict.items() 按键值遍历字典
print(k, v)
#deque双端队列
from collections import deque
queue1 = deque([1, 2, 3])
queue1.append(4) #右端入队
queue1.popleft() #左端弹出并返回值,没有元素会报错
queue1.pop() #右端弹出并返回值,没有元素会报错
#字符串
#正向查找find:返回返回字符串【第一次】出现的位置,如果没有匹配项则返回-1
str.find(str, beg=0, end=len(string))
#反向查找rfind:返回返回字符串【最后一次】出现的位置,如果没有匹配项则返回-1
str.rfind(str, beg=0, end=len(string))
异常处理
try:
# 可能出错的代码
except(Exception1, Exception2, ... ) as e:
# 发生异常时执行
else:
# 正确时执行
finally:
# 无论对错都执行
# 万能异常处理 try + except Exception as e
# 例子
from collections import deque
queue1 = deque()
try:
queue1.pop()
except Exception as e:
print(e) #pop from an empty deque
# 当不需要获取异常信息时,可以不加as
try:
value = int(input("请输入一个整数: "))
except ValueError:
print("输入无效,请输入一个整数")面向对象基础
class Tree:
#类变量,即静态变量,
#赋值时,需要通过Tree来打点赋值才能正确使用
#若使用实例tree打点来赋值,则tree对象自己生成了一个变量count并赋值,并没有更改类的静态变量。
#但访问时,使用类名和实例均可
treeCount = 0
def __init__(self, val, left, right): #构造函数
self.val = val
self.left = left
self.right = right
Tree.treeCount += 1
#定义成员函数时别忘了加一个self参数。如果不加,一般用装饰器@staticmethod修饰,变为静态函数
def displayCount(self):
print ("Total Tree %d" % Tree.treeCount)参数传递与深拷贝
#参数传递:可变类型与不可变类型
#1、不可变类型:值传递,如整数、字符串、元组。
#2、可变类型:引用传递,如 列表,字典。
#浅拷贝,只拷贝父对象,不会拷贝对象的内部的子对象。
b = a.copy()
#深拷贝,完全拷贝了父对象及其子对象。
import copy
c = copy.deepcopy(a)以下为八股(客观题用)
Python语言类型
Python 是强类型的动态脚本语言。
强类型:不允许不同类型相加。
动态:不使用显示数据类型声明,且确定一个变量的类型是在第一次给它赋值的时候。
脚本语言:一般也是解释型语言,运行代码只需要一个解释器,不需要编译。
作者:编程文青李狗蛋
链接:https://www.nowcoder.com/discuss/378581336049594368
来源:牛客网
基本数据类型
Python中分为六种基本数据类型
可变类型(又叫动态数据类型,支持增删改操作):列表(list)、字典(dictionary)、集合(set)
不可变类型(又叫静态数据类型,没有增删改操作):数字(number)、字符串(string)、元组(tuple)
数字类型(Numbers):
数字类型下还可分为整数(int)、浮点数(float)、复数(complex)、布尔(bool)
age = 22 # 整数型,可以通过print(sys.maxsize)查看最大取值范围
print(age) # 输出:22
weight = 116.65 # 浮点型
print(weight) # 输出:116.65
c1 = 1 + 2j
c2 = 2 + 3j
print(c1+c2) # 输出:(3+5j),复数在实际工作中几乎用不到,请自行了解
print(complex(2,1)) # 输出:(2+1j)
print(True == 1) # 输出:True
print(False == 0) # 输出:True
# True==1,False==0 ,因此True 和 False 可以和数字相加
print(True + 1) # 输出:2
print(False - 2) # 输出:-2
# ↓其实布尔型就是整数型的子类,可以使用内置函数issubclass()判断,该函数是用于判断一个类型对象是否是另一个类型对象的子类
print(issubclass(bool, int)) # 输出:True字符串(String)
字符串必须使用''或""括起来,对于特殊字符可以使用反斜杠\进行转义,用+拼接多个字符串, 用*复制字符串,字符串还支持索引截取(又叫切片)
name = "ZhangSan" # 字符串型,也可以使用单括号
print(name) # 输出:ZhangSan
print(name * 2) # 输出字符串两次,也可以写成 print (2 * name),输出:ZhangSanZhangSan
print(name +'-123')# 拼接字符串,输出:ZhangSan-123
print(name +'\'123\'')# 拼接字符串并将单引号转义,输出:ZhangSan'123'
print(name[0:-1]) # 输出第一个至倒数第二个的字符,截取时顾头不顾尾,输出:ZhangSa
print(name[0]) # 输出第一个字符,输出:Z
print(name[-1]) # 输出最后一个字符,输出:n
print(name[2:]) # 输出从第三个开始之后的所有字符,输出:angSan
print(name[0:-1:2]) # 输出第一个至倒数第二个的字符,步长为2,输出:Zaga
print(name[8]) # 若字符不存在,则会抛出IndexError: string index out of range
列表(List)
列表是一组可重复且有序的数据集合,任何类型的数据都可以存到列表中,会根据需要动态分配和回收内存,是Python中使用最频繁的数据类型,列表同样也支持索引截取(又叫切片),列表中的元素是可变的,能够进行增删改操作
# 列表创建
l0 = [] # 创建空列表
l1 = ["张三",'lisi',12,["22","lisi","王武"],"赵柳"] # 直接使用中括号创建列表
l2 = list(['lisi',12,("22","王武"),"赵柳"]) # 或者调用内置函数list(),通常用于转换为列表时使用
# 列表中添加元素
l3 = [1,2]
l4 = ["壹","er"]
l3.append(3) # 在l3列表末尾添加元素3,输出:[1, 2, 3]
l3.append(l4) # 将l4列表添加到l3列表末尾,输出:[1, 2, ['壹', 'er']]
l3.extend("3L") # 在l3列表末尾至少添加两个元素,输出:[1, 2, '3', 'L']
l3.extend(l4) # 将l4列表添加到l3列表末尾,等同于l3+l4,输出:[1, 2, '壹', 'er']
l3.insert(1,"张珊") # 在l3列表中索引为1的位置插入元素,输出:[1, '张珊', 2]
l3.insert(0,l4) # 将l4列表添加到l3列表头部,输出:[['壹', 'er'], 1, 2]
注意三者的区别:
append():指在列表的末尾添加一个元素,新元素会视为一个整体追加到列表末尾
extend():指在列表的末尾至少添加一个元素,新元素会将整体中的每个元素一个一个地追加列表末尾() 类似+号
insert():指在列表的指定索引位置添加元素
元组(Tuple)
元组也是一组可重复且有序的对象集合,任何类型的数据都可以存到元组中,但是元组中的元素是不可变的,元组同样也支持索引截取(又叫切片)
# 创建元组
t0 = () # 创建空元组
t1 = ("张珊","lisi",["李思",12,"Python"],("王武","22")) # 直接使用小括号创建元组
t2 = (1,) # 当元组只有一个元素时需要在后面加上逗号
t3 = tuple(("依儿",22,"Java")) # 或者调用内置函数tuple(),通常用于转换为元组时使用
# 修改元组中的可变对象
t1[2][1] = "十" # 将12改为10
t1[2].remove("Python") # 删除Python元素
t1[2].pop() # 删除最后一个元素
t1[2].clear() # 清空列表
t1[2].append("啊哈") # 添加一个元素
# 拼接元组
print(t2+t3) # 输出:('1', '依儿', 22, 'Java')
字典(Dictionary)
字典是一组可变的无序的对象集合,字典中的元素是通过键(Key) : 值(Value)来保存的,一组键值对称为一个元素,其中键(Key)不可重复,必须唯一,而值(Value)是可重复的,字典会浪费较大内存,是一种使用空间换时间的数据类型
# 创建字典
d0 = {} # 创建空字典
d1 = {"张珊":100,"李思":120,"王武":110} # 使用花括号创建字典
d2 = dict(name="李尔",weight=116) # 调用内置函数dict()创建,通常用于转换为字典时使用
# 获取字典中的元素
print(d1["李思"]) # 使用中括号根据Key获取Value值,输出:120
print(d1["张三"]) # 若Key不存在,则抛出KeyError: '张三'
# ↓还可以使用get()方法取值,此方式若Key不存在则返回None,不会抛出KeyError异常,还可以设置默认Value
print(d1.get("张珊")) # 使用get()方法取值,输出:100
print(d1.get("王武",98)) # 若对应Key不存在则输出默认值,否则输出对应的Value值,此处输出:110
# ↓使用keys()方法获取所有Key
print(d1.keys()) # 获取字典中所有的Key,输出:dict_keys(['张珊', '李思', '王武'])
print(list(d1.keys())) # 获取字典中所有的Key并转为列表,输出:['张珊', '李思', '王武']
print(tuple(d1.keys())) # 获取字典中所有的Key并转为元组,输出:('张珊', '李思', '王武')
# ↓使用values()方法获取所有Value值
print(d1.values()) # 获取字典中所有的Value值,输出:dict_values([100, 120, 110])
print(list(d1.values())) # 获取字典中所有的Value值并转为列表,输出:[100, 120, 110]
print(tuple(d1.values()))# 获取字典中所有的Value值并转为元组,输出:(100, 120, 110)
# ↓使用items()方法获取所有的键值对
print(d1.items()) # 获取字典中所有的Key:Value,输出:dict_items([('张珊', 100), ('李思', 120), ('王武', 110)])
print(list(d1.items())) # 获取字典中所有的Key:Value并转为列表,输出:[('张珊', 100), ('李思', 120), ('王武', 110)]
print(tuple(d1.items())) # 获取字典中所有的Key:Value并转为元组,输出:(('张珊', 100), ('李思', 120), ('王武', 110))
for item in d1: # 直接使用for循环遍历,遍历得到的是Key
print(item) # 返回字典中所有的Key
for k, v in knights.items(): # 而遍历dict.items() ,是按Key:Value遍历字典
print(k, v)集合(set)
集合是一组可变的、无序的且不可重复的元素序列
# 创建集合
s0 = set() # 创建空集合,不能直接使用花括号,花括号默认是创建字典
s1 = {"李思","张珊","李思","王武"} # 花括号中元素非键值对时,创建的是集合
s2 = set("李尔") # 调用内部函数set()创建,通常用于转换为集合时使用
#添加元素
set1.add(5)
#移除元素,如果元素不存在会发生错误
s.remove(x)
#移除元素,不存在不会报错
s.discard(x)
#set遍历可使用简单的for in
for i in s:
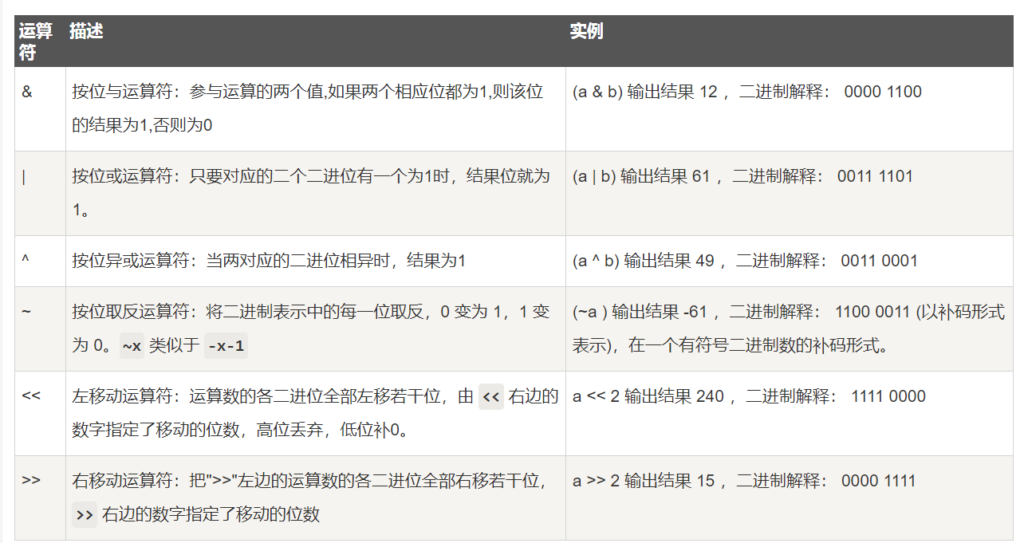
print i位运算符
- & 按位与
- | 按位或
- ^ 异或
- ~ 按位取反
- << 左移
- >> 右移
变量作用域
变量的作用域可以分为四种:局部作用域、嵌套作用域、全局作用域和内置作用域,这四种作用域遵循 LEGB 原则。
# 1. 局部作用域(Local)
# 局部作用域中的变量是在函数内部定义的,只能在该函数内部访问。
def my_function():
x = 10 # 局部变量
print(x) # 输出: 10
my_function()
print(x) # 报错,x 在函数外部不可访问
# 2. 嵌套作用域(Enclosing)
# 嵌套作用域是指函数内部的函数可以访问外层函数的变量,但无法修改它(除非使用 nonlocal 关键字)。
def outer_function():
x = 5 # 外层函数的局部变量
def inner_function():
print(x) # 内层函数可以访问外层函数的局部变量
inner_function()
outer_function() # 输出: 5
# 3. 全局作用域(Global)
# 全局变量是在函数之外定义的,可以在整个模块中访问。如果在函数内部要修改全局变量,必须使用 global 关键字。
x = 20 # 全局变量
def my_function():
print(x) # 在函数内部访问全局变量
my_function() # 输出: 20
# 4. 内置作用域(Built-in)
# 内置作用域包含 Python 解释器内置的变量,如 len()、range() 等。可以在任何地方访问这些内置的函数或常量。
print(len([1, 2, 3])) # 内置函数 len(),输出: 3
LEGB 规则
Python 变量作用域的查找顺序是:
- Local(局部作用域):当前函数内定义的变量。
- Enclosing(嵌套作用域):外部嵌套函数的变量。
- Global(全局作用域):模块顶级定义的变量(即整个文件)。
- Built-in(内置作用域):Python 预定义的变量和函数,如
len、str。
查找变量时,Python 会按照这个顺序逐层查找,直到找到变量。如果未找到,则抛出 NameError。
模块导入
# 导入方式
# import
# import ... as ...
# from ... import ...
# from ... import *
# 使用前两种方式 需要使用模块名.类名.方法
# 例子:导入datetime模块里的datetime类
from datetime import datetime
print(datetime.now())字典键值
Python的字典(dict)底层基于哈希表,值可以取任何数据类型,但键必须是不可变的,如字符串、数字,甚至元组也可以
可变对象与不可变对象
不可变对象: bool,int,float,tuple,str…
可变对象: list,dict,set
函数可变参数传递
用来处理可变参数,接收参数后,args会变成一个tuple,kwargs会变成一个dict
元组初始化
使用括号的方式初始化单元素元组时,需要添加一个逗号,否则括号会被认为是运算符。
a=(1,) # 正确
a=(1) # 错误三元表达式
condition_is_true if condition else condition_is_false
condition_is_true if condition else condition_is_false
# 例子
max = num if num>max else maxlambda(匿名函数)
Python 使用 lambda 来创建匿名函数。
lambda 函数是一种小型、匿名的、内联函数,它可以具有任意数量的参数,但只能有一个表达式。
匿名函数不需要使用 def 关键字定义完整函数。
lambda 函数通常用于编写简单的、单行的函数,通常在需要函数作为参数传递的情况下使用,例如在 map()、filter()、reduce() 等函数中。
# 无输入参数
f = lambda: "Hello, world!"
print(f()) # 输出: Hello, world!
# 有输入参数
x = lambda a : a + 10
print(x(5)) # 输出:15
x = lambda a, b : a * b
print(x(5, 6)) # 输出:30lambda 函数通常与内置函数如 map()、filter() 和 reduce() 一起使用,以便在集合上执行操作。例如:
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
print(squared) # 输出: [1, 4, 9, 16, 25]常见模块使用
sys模块
- sys.argv:可以用
sys.argv获取当前正在执行的命令行参数的参数列表(list)。- sys.argv[0] 当前程序名
- sys.argv[1] 第一个参数
- sys.argv[0] 第二个参数
- …以此类推
参考代码
# encoding: utf-8
# filename: argv_test.py
import sys
# 获取脚本名字
print 'The name of this program is: %s' %(sys.argv[0])
# 获取参数列表
print 'The command line arguments are:'
for i in sys.argv:
print i
# 统计参数个数
print 'There are %s arguments.'%(len(sys.argv)-1)输出结果
The name of this program is: argv_test.py
The command line arguments are:
argv_test.py
arg1
arg2
arg3
There are 3 arguments.- sys.platform:获取当前执行环境的平台,如
win32表示是Windows 32bit操作系统,linux2表示是linux平台; - sys.path:path是一个目录列表,供Python从中查找第三方扩展模块。在python启动时,
sys.path根据内建规则、PYTHONPATH变量进行初始化。 - sys.exit(n):调用
sys.exit(n)可以中途退出程序,当参数非0时,会引发一个SystemExit异常,从而可以在主程序中捕获该异常。
os模块
os 模块常用方法 相应的作用
- os.chdir(path) 改变当前工作目录,path必须为字符串形式的目录
- os.getcwd() 返回当前工作目录
- os.listdir(path) 列举指定目录的文件名
- os.mkdir(path) 创建path指定的文件夹,只能创建一个单层文件,而不能嵌套创建,若文件夹存在则会抛出异常
- os.makedirs(path) 创建多层目录 ,可以嵌套创建
- os.move(file_name) 删除指定文件
- os.rmdir(path) 删除单层目录,遇见目录非空时则会抛出异常
- os.removedirs(path) 逐层删除多层目录
- os.rename(old,new) 文件old重命名为new
- os.system(command) 运行系统的命令窗口
- os.walk(dir)以递归的方式遍历文件夹,返回值为迭代器对象,每个对象为一个三元组(dirpath, dirnames, filenames),dirpath为目录,dirnames为这个目录下的子目录名,filenames为这个目录下的所有文件名
os.path 模块常用方法 相应的作用
- abspath(path) 返回文件或目录的绝对路径
- basename(path) 返回path路径最后一个\后的内容,可以为空
- dirname(path) 返回path路径最后一个\之前的内容
- split(path) 返回一个(head,tail)元组,head为最后\之前的内容;tail为最后\之后的内容,可以为空
- splitext(path) 返回指向文件的路径和扩展名
- exists(path) 查询路径path是否存在
- isabs(s) 判断指定路径s是否为绝对路径
- isdir(path) 判断path指向的是否是文件夹
- isfile(path) 判断path是否指向文件
- join(path,*path) 将两个path通过\组合在一起,或将更多path组合在一起
- getatime(filename) 返回文件的最近访问时间,返回的是浮点数时间
- getctime(filename) 返回文件的创建时间
- getmtime(filename) 返回文件的修改时间
datetime模块
- datetime.now() 返回当前的日期和时间。
import datetime
now = datetime.datetime.now()
print(now) # 如:2024-10-14 10:45:23.123456- datetime.strptime() 将字符串解析为 datetime 对象。需要指定格式化字符串。
import datetime
date_string = "2024-10-14 10:45:23"
date_object = datetime.datetime.strptime(date_string, "%Y-%m-%d %H:%M:%S")
print(date_object) # 2024-10-14 10:45:23- datetime.strftime() 将 datetime 对象格式化为字符串。
import datetime
now = datetime.datetime.now()
date_string = now.strftime("%Y-%m-%d %H:%M:%S")
print(date_string) # 如:2024-10-14 10:45:23- datetime.timedelta() 用于时间的加减法操作。可以表示时间的差值,如天数、小时、分钟等。
import datetime
now = datetime.datetime.now()
delta = datetime.timedelta(days=5)
future = now + delta # 5天后
print(future) # 如:2024-10-19 10:45:23time模块
- time.time() 返回当前时间的时间戳(从 Unix 纪元(1970年1月1日)开始的秒数)。
import time
timestamp = time.time()
print(timestamp) # 如:1697255179.123456- time.sleep() 使程序暂停执行指定的秒数。
import time
print("Start")
time.sleep(2) # 程序暂停 2 秒
print("End")- time.localtime() 将时间戳转换为结构化的本地时间(struct_time 对象)。
import time
local_time = time.localtime()
print(local_time) # 如:time.struct_time(tm_year=2024, tm_mon=10, tm_mday=14, ...)- time.strftime() 根据格式化字符串将 struct_time 或时间戳转换为可读的时间字符串。
import time
formatted_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print(formatted_time) # 如:2024-10-14 10:45:23io和读写文件
f = open(filename, mode='r')
# file: 文件路径(字符串)。可以是相对路径或绝对路径。
# mode: 文件打开模式,决定了文件如何被处理。常见模式有:
'r': 以只读模式打开(默认)。
'w': 以写入模式打开,如果文件不存在会创建文件;如果文件存在则清空文件。
'a': 以追加模式打开,数据会被写入到文件末尾。
'b': 以二进制模式打开(可以与其他模式一起使用,如 'rb'、'wb')。
't': 以文本模式打开(默认,与其他模式组合使用,如 'rt')。
'x': 以独占创建模式打开,文件不存在则创建,存在则引发错误。
'+': 打开文件进行更新(读和写),可以与其他模式组合使用,如 'r+'、'w+' 等。
# 常见用法
# 读取文件内容
with open('example.txt', 'r') as file:
content = file.read()
print(content)
# 写入文件
with open('example.txt', 'w') as file:
file.write('Hello, World!')
# 追加写入文件
with open('example.txt', 'a') as file:
file.write('\nAppending this line.')
# 逐行读取文件
with open('example.txt', 'r') as file:
for line in file:
print(line.strip()) # 去除换行符
# 使用 with open(...) as 是推荐方式,因为它会在 with 块结束时自动关闭文件,防止资源泄漏。
# 如果不使用with open,直接f = open(),则需要f.close()手动关闭
# 此外open()还可以加上 encoding='utf-8'参数,以防止编码问题